


- Botpress 提供透明的定价,无隐藏 AI 费用,让您的 AI 成本仅反映真实用量。
- 缓存 AI 响应可在不影响用户体验的前提下,将查询成本降低约 30%。
- 选择合适的 AI 模型(如优先使用 GPT-3.5 Turbo 而非 GPT-4)对于平衡成本与质量至关重要。
许多企业都面临着利用 AI 技术潜力又不想超支的挑战。我们理解这种平衡的重要性,并致力于为用户提供能够高性价比利用 AI 的解决方案。
我们的 AI 成本管理方法
首先,了解我们如何在为用户提供 AI 能力的同时降低相关成本的两个关键要素非常重要。
透明定价:无隐藏费用
我们不会对 AI 相关任务加收任何额外费用。这意味着您的 AI 花费成本与实际用量直接相关,我们不会额外收取 AI 费用。
缓存 AI 响应
缓存是我们降低机器人 AI 成本最有效的策略之一。通过缓存 AI 响应,我们减少了对 LLM 提供商的请求次数,从而将查询成本降低约 30%,为您节省资金,同时不影响机器人与用户的互动质量。
优化 AI 成本的小贴士
既然我们已经了解了两种降低用户 AI 花费的方法,下面介绍在构建机器人时还能进一步降低 AI 成本的实用建议。
优化您的知识库
优化知识库(KB)对 AI 花费影响极大,因为在 Botpress 项目中,知识库通常是最大的 AI 成本来源。
建议一:选择合适的 AI 模型
AI 模型的选择对成本影响显著。由于 GPT-3.5 Turbo 比 GPT-4 Turbo 更快且更便宜,我们建议在考虑升级到更高级版本前,先用 GPT-3.5 Turbo 充分测试您的配置。
我们的 KB Agent 混合模式提供了一个很好的折中方案:我们会先用 GPT-3.5 Turbo 回答问题,只有在必要时才升级到 GPT-4 Turbo。
建议二:为知识库加“防护罩”
通过使用“查找记录”卡片将常见 FAQ 从知识库中隔离,可以减少不必要的 AI 花费。如果您知道用户通常会问某些问题,并且我们有 50 个已知问题及答案,可以将它们加入表格,并用“查找记录”卡片查询。只有找不到答案时,才查询知识库。
建议三:合理划分知识库范围
根据您想添加到知识库中的信息类型和数量,通常建议同时做两件事以降低 AI 成本:一是将信息整理为多个小型知识库,每个知识库聚焦于特定产品、功能或主题;二是通过多轮提问引导用户,逐步缩小搜索范围到具体知识库。这样不仅能降低成本,还能获得更优结果。
建议四:网站知识库数据源与网页搜索知识库数据源
如果您以网站作为知识库数据源,但网站内容并不经常变动且无需实时同步到机器人,那么可以考虑用“网页搜索”作为知识库数据源,替代“网站知识库”数据源。在切换前,请确保常见问题的表现不会因切换而变差。
建议五:用“查找记录”或“执行代码”卡片查询表格
如果您有一个需要查询的数据表,建议优先用“查找记录”卡片,而不是将表格作为知识库的一部分。对于有技术能力的用户,直接用“执行代码”卡片查询表格并将结果存入工作流变量,会更加高效且节省成本。
建议六:控制分块数量
这里的“分块”指的是从知识库中检索用于生成答案的内容块数量。一般来说,检索的分块越多,答案越准确,但生成时间越长且消耗更多 AI 令牌。建议通过调整分块大小,找到既能保证准确性又能降低成本的最优点。
用“执行代码”卡片降低 AI 花费
“执行代码”卡片可以在某些场景下替代部分 AI 卡片,且更具成本效益。以下是一些适用场景:
更智能的消息替代方案
如果您希望机器人每次对同一问题都给出不同的 AI 回应,必须禁用缓存(具体方法见附录)。有些场景下,提升对话体验所带来的 AI 花费增加是值得的,但并非总是如此。
比如用 LLM 生成简单问候语,每次问候都会产生额外 AI 成本。这样做值得吗?大概率不值得。幸运的是,有一种更经济的做法:用一个包含多条回复的数组,再用简单函数随机选取并展示。
根据对话量的不同,采用这种方法节省的成本可能非常可观。
您可以在这里查看更多替代消息的实现细节。
简单任务的代码执行
对于如数据重组、从结构化数据中提取信息等简单任务,使用“执行代码”卡片比依赖 LLM 更高效、更便宜、更快捷。
摘要代理的替代方案
您可以用“执行代码”卡片自定义会话记录。在需要记录用户和机器人消息的地方插入“执行代码”卡片,将消息存入数组变量,之后可将该数组作为知识库的上下文使用。
能简化就简化
选择能实现同样目标且不会影响用户体验的更简单交互方式。例如,收集用户反馈时,采用带评论的星级评分系统比用 AI 收集同类信息更经济。
AI 任务、AI 生成文本与翻译的建议
选择合适的 AI 模型
没错,选择合适的 AI 模型非常重要,值得再次强调。与知识库类似,AI 任务中模型选择对成本影响极大。对于不复杂的指令,优先选择 GPT-3.5 Turbo。在考虑升级到更高级版本前,务必用该模型充分测试。请记住,GPT-4 Turbo 的成本是 GPT-3.5 Turbo 的 20 倍。除非效果明显更好,否则建议优先用 GPT-3.5 Turbo。
此外,还可以通过减少每次 AI 任务运行时消耗的令牌数来节省 AI 花费。
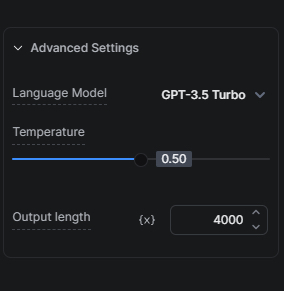
我的建议是有意识地减少令牌数,因为超出部分会被截断。例如,如果将长度限制为 2000 令牌,而提示词加输出超过 2000,则输入会被相应截断。
AI 任务 vs AI 生成文本
对于简单文本输出,“AI 生成文本”卡片消耗更少令牌且设置更简单;而涉及信息解析时,“AI 任务”卡片表现更优。
因此,建议在需要用 AI 处理信息(如识别用户意图或分析输入)时使用“AI 任务”卡片;如果只是用 AI 生成文本(如扩展知识库答案或创意生成问题),则用“AI 生成文本”卡片。
如需深入了解“AI 任务”卡片与“AI 生成文本”卡片的区别,请点击这里了解更多。
翻译
如果您的机器人需要处理大量多语言对话,建议集成外部翻译服务的钩子,以获得更具成本效益的方案。
您可以在这里查看更多关于钩子的资料。
结尾
通过这些策略和建议,您可以在 Botpress 中优化 AI 花费。了解不同任务的成本影响,并为您的需求选择最高效的方法,将帮助您在不影响性能的前提下降低 AI 相关支出。
我们的团队随时为您提供帮助,协助您选择合适的方案,确保您的机器人以最高效的成本为用户带来最佳体验。欲了解更多信息,请访问我们的价格页面,或加入我们的 Discord 服务器获取帮助。
附录
如何防止缓存
如果您希望避免缓存,总是获得实时结果,可以选择以下任一方法:
- 如需长期防止缓存:请在所有与 AI 相关的卡片中(如 AI 任务提示、知识库上下文等)添加 `And discard:{{Date.now()}}`。
- 如需临时防止缓存:请发布您的机器人,并在无痕窗口中进行测试。
注意:在其他条件不变的情况下,移除此缓存层且不对机器人做其他更改,AI 使用成本将会上升。
推荐课程
- ChatGPT 提示工程师课程(面向开发者)(虽然标题写的是面向开发者,非开发者同样受益!)
- 使用 ChatGPT API 构建系统


.webp)

