



- ASR 通过机器学习将语音转化为文本,实现语音指令和实时转录。
- 现代 ASR 系统已从独立的音素模型(HMM-GMM)转向能够预测完整单词的深度学习模型。
- ASR 的性能通过词错误率(WER)来衡量,错误包括替换、删除或插入;WER 越低,转录质量越好。
- ASR 的未来将聚焦于本地设备处理以保护隐私,并支持资源较少的语言。
你上一次看没有字幕的视频是什么时候?
字幕曾经是可选项,但现在无论我们是否需要,它们都出现在短视频中。字幕已经深深融入内容中,以至于你会忘记它们的存在。
自动语音识别(ASR)——能够快速、准确地自动将口语转换为文本的技术——正是推动这一变化的核心。
当我们想到一个AI 语音助手时,我们会关注它的用词、表达方式以及它的声音。
但我们很容易忽略,流畅的互动其实依赖于机器人能否理解我们。而要让机器人在嘈杂环境中听懂你说话时的“嗯”“啊”,并不容易。
今天,我们来聊聊驱动这些字幕背后技术:自动语音识别(ASR)。
请允许我自我介绍:我拥有语音技术硕士学位,业余时间喜欢了解 ASR 的最新进展,甚至还会自己动手开发项目。
我会为你讲解 ASR 的基础知识,带你了解背后的技术,并大胆预测一下未来的发展方向。
什么是 ASR?
自动语音识别(ASR),也叫语音转文本(STT),是通过机器学习技术将语音转换为书面文本的过程。
涉及语音的技术通常都会在某种程度上集成 ASR;比如视频加字幕、将客户支持通话转录用于分析,或作为语音助手交互的一部分等。
语音转文本算法
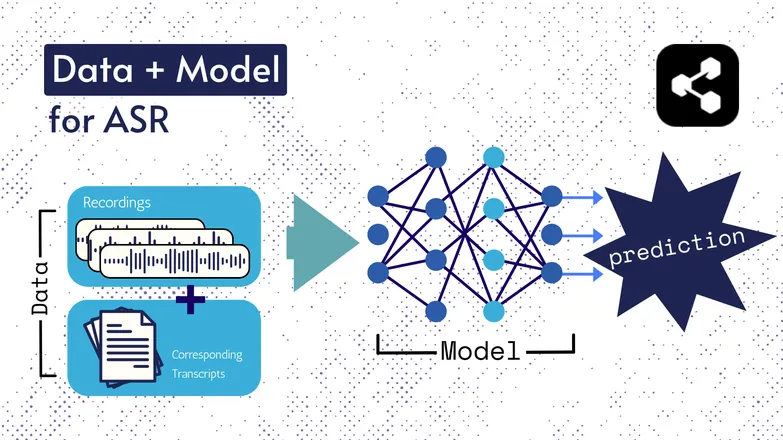
底层技术这些年来不断变化,但所有版本基本都包含两个要素:数据和模型。
在 ASR 中,数据指的是带标签的语音——即带有对应转录文本的语音音频文件。
模型是用于根据音频预测转录文本的算法。带标签的数据用于训练模型,使其能够泛化到未见过的语音样本。
这就像你即使从未听过某些单词的排列顺序,或者是陌生人说的话,你也能理解。
同样,模型的类型和细节随着时间不断变化,所有速度和准确率的提升都归因于数据集和模型的规模与配置。
小知识:特征提取
我在关于文本转语音的文章中提到过特征或表示。这些在过去和现在的 ASR 模型中都被使用。
特征提取——将语音转换为特征——几乎是所有 ASR 流程的第一步。
简而言之,这些特征,通常是声谱图,是对语音进行数学运算后的结果,将语音转换为一种能突出同一句话内部相似性、减少不同说话人之间差异的格式。
也就是说,即使两位说话人声音差异很大,说同一句话时的声谱图也会很相似。
我特别说明这一点,是想让你知道我后面会说模型“根据语音预测转录文本”。其实更准确地说,模型是根据特征来预测的。但你可以把特征提取看作模型的一部分。
早期 ASR:HMM-GMM
隐马尔可夫模型(HMM)和高斯混合模型(GMM)是深度神经网络普及前的预测模型。
HMM 曾长期主导 ASR 领域。
对于一段音频,HMM 预测音素的持续时间,GMM 预测具体的音素。
听起来有点反过来了,实际上也确实如此,比如:
- HMM:“前0.2秒是一个音素。”
- GMM:“这个音素是G,就像Gary里的 G。”
要把音频片段转成文本,还需要额外几个组件,主要包括:
- 发音词典:词汇表中所有单词及其对应发音的详尽列表。
- 语言模型:词汇表中单词的组合及其共现概率。
所以即使 GMM 预测 /f/ 而不是 /s/,语言模型也知道说话者更可能说的是“a penny for your thoughts”,而不是foughts。
之所以有这么多部分,直白说,这个流程里没有哪一环特别靠谱。
HMM 会对齐错误,GMM 会把相似的音混淆:/s/ 和 /f/、/p/ 和 /t/,元音更是不用说了。
然后语言模型会把这些杂乱无章的音素修正成更像语言的内容。
端到端 ASR 与深度学习
ASR 流程中的许多部分如今已被整合。
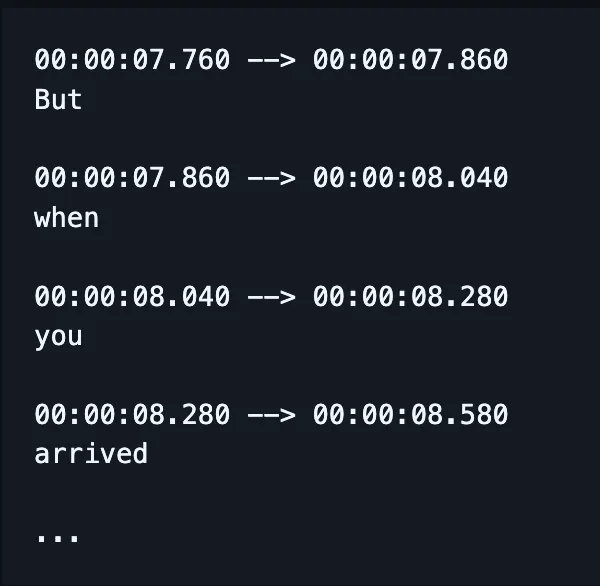
现在不再需要分别训练拼写、对齐和发音等多个模型,而是一个模型直接输入语音,输出(理应)拼写正确的单词,并且现在还能输出时间戳。
(不过实际应用中通常会用额外的语言模型对输出进行修正或“重评分”。)
这并不意味着对齐、拼写等不同因素就不再被单独关注。依然有大量文献专注于针对性地解决某些具体问题。
也就是说,研究者会提出针对模型结构的改进方法,专门优化某些性能因素,比如:
- 基于前序输出条件的 RNN-Transducer 解码器,用于提升拼写准确率。
- 卷积下采样以减少空白输出,从而提升对齐效果。
我知道这些听起来很难懂。我只是提前回应老板可能会问“能不能举个通俗点的例子?”
答案是不能。
真的不能。
ASR 的性能如何衡量?
ASR 表现差的时候你一听就知道。
我见过caramelization被转录成communist Asians,Crispiness变成Chris p —,你懂的。
我们用来量化错误的指标是词错误率(WER)。WER 的计算公式如下:
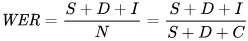
其中:
- S 表示替换的数量(将预测文本中的单词更改为参考文本中的单词)
- D 表示删除的数量(输出中缺少的单词,相较于参考文本)
- I 表示插入的数量(输出中多出的单词,相较于参考文本)
- N 是参考文本中的总单词数
比如,参考文本是“the cat sat.”
- 如果模型输出“the cat sank”,这是一次替换。
- 如果模型输出“cat sat”,这是一次删除。
- 如果输出“the cat has sat”,这是一次插入。
ASR 有哪些应用?
ASR 是个很实用的工具。
它还通过提升安全性、可访问性和关键行业的效率,改善了我们的生活质量。
医疗健康
每当我告诉医生我做语音识别研究时,他们都会说“哦,像Dragon那样的?”
在我们拥有医疗领域的生成式人工智能之前,医生们只能以每分钟30个单词的速度用有限的词汇量进行口头记录。
自动语音识别(ASR)在缓解医生普遍的职业倦怠方面取得了巨大成功。
医生们需要在大量文书工作和照顾患者之间取得平衡。早在2018年,研究人员就曾呼吁在会诊中使用数字转录,以提升医生的诊疗能力。
这是因为事后记录会诊内容不仅会减少与患者面对面的时间,而且比基于实际会诊转录的摘要准确性要低得多。
智能家居
我有个小笑话。
当我想关灯但又懒得起身时,我会快速拍两下手——就像我有个声控开关一样。
我的伴侣从来不笑。
语音激活的智能家居既让人觉得未来感十足,又让人觉得有点奢侈。至少表面上如此。
当然,它们很方便,但在很多情况下,它们让原本无法实现的事情变得可能。
一个很好的例子是能源消耗:如果你需要频繁起身调节灯光和恒温器,全天进行微调几乎不现实。
语音激活不仅让这些微调变得更简单,还能理解人类语言的细微差别。
比如你说“能不能稍微凉快一点?”助手会利用自然语言处理将你的请求转化为温度变化,同时还会考虑许多其他数据:当前温度、天气预报、其他用户的恒温器使用数据等。
你只需要做好你该做的事,其余的交给计算机处理。
我认为这比你凭感觉猜要调低多少度要容易得多。
而且它更加节能:有报道称,家庭使用语音控制的智能照明后,能耗降低了80%,这只是其中一个例子。
客户支持
我们在医疗领域已经讨论过这个问题,但“转录加摘要”比人们事后总结互动内容要有效得多。
同样,这样做既节省时间,也更准确。我们一次又一次地发现,自动化能让人们有更多时间把工作做得更好。
在客户支持领域,这一点尤为明显,采用ASR技术的客户支持首呼解决率提高了25%。
转录和摘要有助于自动化根据客户情绪和问题寻找解决方案的过程。
车载助手
我们这里其实是在借鉴家庭助手的思路,但这确实值得一提。
语音识别能减轻驾驶员的认知负担,减少视觉干扰。
而分心因素导致的碰撞事故高达30%,因此应用这项技术无疑能提升安全性。
言语病理学
ASR长期以来一直被用作评估和治疗言语障碍的工具。
我们要记住,机器不仅能自动化任务,还能完成一些人类无法做到的事情。
语音识别可以检测到几乎难以用人耳察觉的语音细微差别,捕捉到受影响语音的具体特征,否则这些特征很容易被忽略。
ASR的未来
语音转文字(STT)已经足够成熟,以至于我们几乎不会再去刻意关注它。
但在幕后,研究人员仍在努力让它变得更强大、更易用——而且更不易察觉。
我挑选了一些利用ASR进步的令人兴奋的趋势,并加入了我的一些看法。
端侧语音识别
大多数ASR解决方案都运行在云端。你肯定听说过。这意味着模型运行在远程计算机上,在别的地方。
之所以这样做,是因为你的手机处理器未必能运行庞大的模型,或者转录会非常慢。
因此,你的音频会通过互联网发送到远程服务器,该服务器配备了你口袋里带不动的GPU。GPU运行ASR模型,然后把转录结果返回到你的设备。
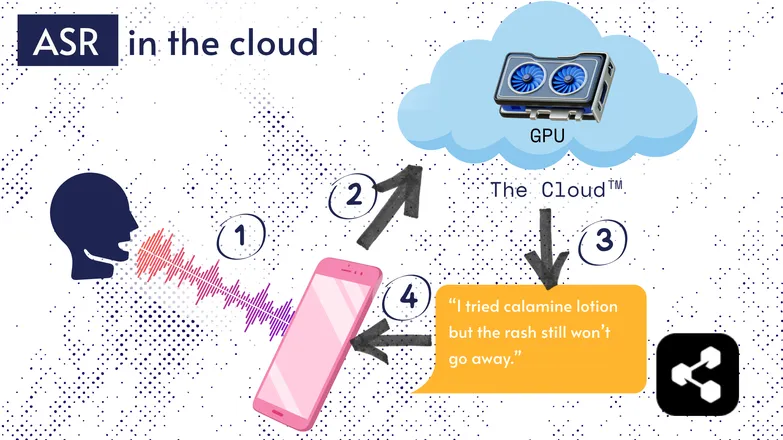
出于能效和安全的考虑(并不是每个人都希望自己的个人数据在网络上流转),大量研究致力于让模型足够小巧,可以直接在你的设备上运行,无论是手机、电脑还是浏览器引擎。
我本人写过一篇关于ASR模型量化以便端侧运行的论文。Picovoice是一家加拿大公司,专注于构建低延迟端侧语音AI,看起来很不错。
端侧ASR让转录服务成本更低,有望惠及低收入群体。
以转录为核心的界面
音频与转录之间的距离正在缩小。这意味着什么?
像Premiere Pro和Descript这样的剪辑软件允许你通过转录文本导航录音:点击某个单词就能跳转到对应的时间点。
需要多录几遍?像文本编辑器一样,挑选你最满意的一条,把其余的删除。系统会自动帮你剪辑视频。
用波形图做这种编辑很让人头疼,但有了基于转录的编辑器就变得非常简单。
类似地,WhatsApp等消息服务正在转录你的语音消息,并允许你通过文本滑动浏览。手指滑到哪个词,就能跳到录音的相应部分。

有个有趣的故事:大约在苹果发布类似功能前一周,我其实就做了一个类似的东西。
这些例子展示了复杂的底层技术如何为终端用户应用带来简洁和直观体验。
公平、包容与低资源语言
这场战斗还远未结束。
ASR在英语和其他常见、资源丰富的语言中表现出色。但对于低资源语言来说,情况并非如此。
在方言少数群体、受影响语音以及语音技术公平性等方面仍存在差距。
很抱歉打破好心情。这一节叫做ASR的“未来”。我选择期待一个值得我们自豪的未来。
如果我们要进步,就应该共同前行,否则只会加剧社会不平等。
立即开始使用ASR
无论你的业务是什么,使用ASR都是明智之选——但你可能会想,如何开始?ASR该怎么集成?又如何将这些数据传递给其他工具?
Botpress自带易用的转录卡片。它们可以集成到拖拽式流程中,并可通过数十种应用和通信渠道进行扩展集成。
立即开始构建。永久免费。
常见问题
现代ASR在不同口音和嘈杂环境下的准确率如何?
现代ASR系统在主流语言的常见口音下表现非常出色,在清晰环境下词错误率(WER)低于10%,但遇到重口音、方言或明显背景噪音时,准确率会明显下降。谷歌、微软等厂商会用多样化语音数据训练模型,但在嘈杂环境下实现完美转录仍然是个挑战。
ASR在转录专业术语或行业专有词汇时可靠吗?
ASR在处理专业术语或行业专有词汇时,开箱即用的准确率较低,因为其训练数据通常偏向通用语音;不熟悉的词汇可能会被误转或遗漏。不过,企业级解决方案支持自定义词汇表、领域专用语言模型和发音词典,可提升医疗、法律、工程等领域的技术词汇识别能力。
免费ASR工具和企业级解决方案有什么区别?
免费ASR工具与企业级解决方案的区别在于准确率、可扩展性、定制化和隐私控制:免费工具通常错误率更高、语言支持有限且有使用限制,而企业级方案则提供更低的WER、领域定制、集成、服务级协议(SLA)以及强大的安全功能以处理敏感数据。
ASR在转录过程中如何保护用户隐私和敏感信息?
ASR通过在数据传输过程中加密来保护用户隐私,并提供如本地运行模型等选项,以避免将语音数据发送到外部服务器。许多企业级服务商还遵守GDPR或HIPAA等隐私法规,并可对数据进行匿名化处理,以保障敏感信息安全。
云端ASR服务与本地部署方案相比,费用如何?
基于云的ASR服务通常按音频分钟数或使用量阶梯计费,费用从每分钟$0.03到$1.00以上不等,具体取决于准确率和功能;而本地部署的解决方案则涉及前期开发成本和授权费用。



