.webp)


- O RAG combina a recuperação de dados confiáveis com a geração por LLM, garantindo que as respostas da IA sejam precisas, relevantes e baseadas no conhecimento real do negócio.
- Diferente dos LLMs puros, o RAG reduz alucinações ao fundamentar as respostas em documentos, bancos de dados ou conteúdos aprovados.
- O RAG permite acesso a informações atualizadas, possibilitando que sistemas de IA respondam sobre mudanças recentes ou temas de nicho além dos dados estáticos de treinamento de um LLM.
- Manter um sistema RAG envolve atualizar os dados, monitorar as respostas e aprimorar os métodos de recuperação para garantir o melhor desempenho ao longo do tempo.
O RAG permite que organizações usem IA com menos riscos do que o uso tradicional de LLMs.
A geração aumentada por recuperação está se tornando mais popular à medida que mais empresas adotam soluções de IA. Os primeiros chatbots corporativos apresentaram erros arriscados e alucinações.
O RAG permite que empresas aproveitem o poder dos LLMs enquanto fundamentam as respostas geradas no conhecimento específico do seu negócio.
O que é geração aumentada por recuperação?
Geração aumentada por recuperação (RAG) em IA é uma técnica que combina a) busca de informações externas relevantes e b) respostas geradas por IA, melhorando a precisão e relevância.
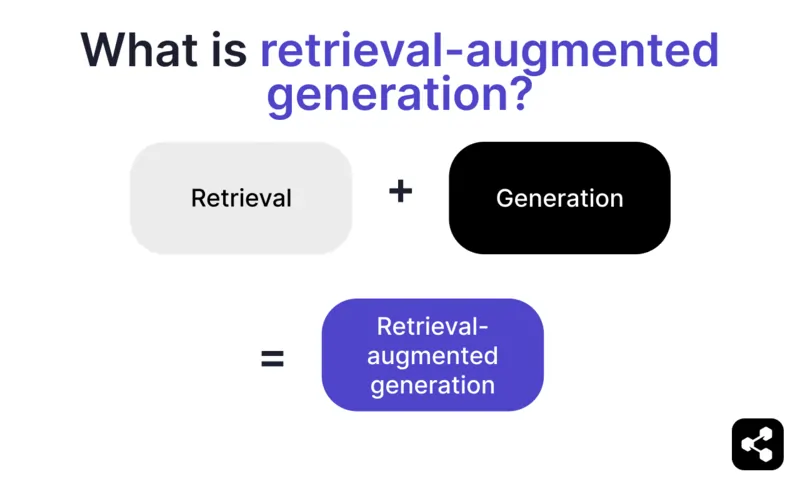
Em vez de depender apenas da geração dos modelos de linguagem (LLMs), as respostas dos modelos RAG são baseadas em bases de conhecimento definidas pelo criador do agente de IA – como o site da empresa ou um documento de políticas de RH.
O RAG funciona em dois passos principais:
1. Recuperação
O modelo busca e recupera dados relevantes de fontes estruturadas ou não estruturadas (por exemplo, bancos de dados, PDFs, arquivos HTML ou outros documentos). Essas fontes podem ser estruturadas (como tabelas) ou não estruturadas (como sites aprovados).
2. Geração
Após a recuperação, as informações são enviadas ao LLM. O LLM utiliza esses dados para gerar uma resposta em linguagem natural, combinando as informações aprovadas com sua capacidade linguística para criar respostas precisas, naturais e alinhadas à marca.
Exemplos de uso do RAG
Qual o objetivo do RAG? Permitir que organizações forneçam respostas relevantes, informativas e precisas.
O RAG é uma maneira direta de reduzir o risco de respostas imprecisas ou alucinações dos LLMs.
Exemplo 1: Escritório de advocacia
Um escritório de advocacia pode usar um sistema de IA com RAG para:
- Buscar jurisprudências, precedentes e decisões legais relevantes em bancos de dados de documentos durante pesquisas.
- Gerar resumos de casos extraindo fatos importantes de arquivos e decisões anteriores.
- Fornecer automaticamente aos funcionários atualizações regulatórias relevantes.
Exemplo 2: Imobiliária
Uma imobiliária pode usar um RAG em um sistema de IA para:
- Resumir dados de históricos de transações de imóveis e estatísticas de criminalidade do bairro.
- Responder dúvidas jurídicas sobre transações imobiliárias citando leis e regulamentos locais.
- Agilizar avaliações de imóveis puxando dados de laudos, tendências de mercado e vendas anteriores.
Exemplo 3: Loja de E-commerce
Uma loja de e-commerce pode usar um sistema de IA com RAG para:
- Coletar informações de produtos, especificações e avaliações no banco de dados da empresa para oferecer recomendações personalizadas.
- Recuperar histórico de pedidos para criar experiências de compra personalizadas de acordo com as preferências do usuário.
- Gerar campanhas de e-mail segmentadas recuperando dados de segmentação de clientes e combinando com padrões recentes de compra.
Vantagens do RAG
Como qualquer pessoa que já usou o ChatGPT ou o Claude sabe, LLMs possuem poucas proteções embutidas.
Sem supervisão adequada, eles podem gerar informações imprecisas ou até prejudiciais, tornando-os pouco confiáveis para aplicações no mundo real.
O RAG resolve esse problema ao fundamentar as respostas em fontes de dados confiáveis e atualizadas, reduzindo significativamente esses riscos.
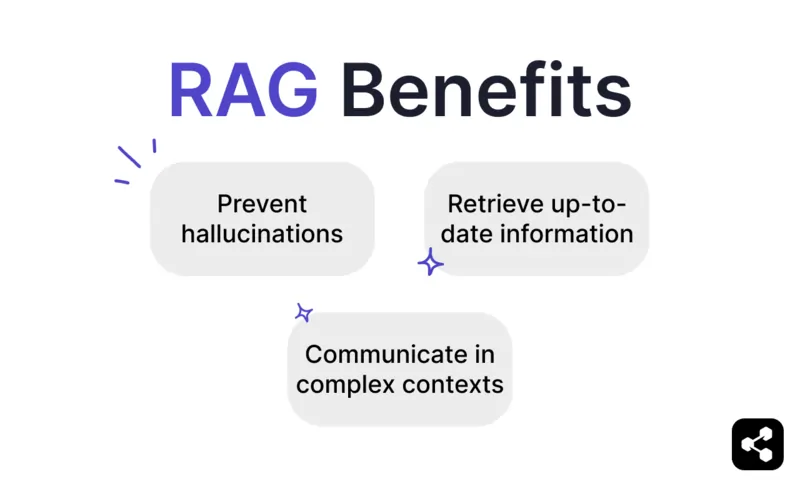
Evite alucinações e imprecisões
Modelos de linguagem tradicionais frequentemente geram alucinações — respostas que parecem corretas, mas são incorretas ou irrelevantes.
O RAG reduz as alucinações ao fundamentar as respostas em fontes de dados confiáveis e altamente relevantes.
A etapa de recuperação garante que o modelo consulte informações precisas e atualizadas, o que diminui muito as chances de alucinações e aumenta a confiabilidade.
Recupere informações atualizadas
Embora LLMs sejam ferramentas poderosas para várias tarefas, eles não conseguem fornecer informações precisas sobre dados raros ou recentes – incluindo conhecimento específico do negócio.
Já o RAG permite que o modelo obtenha informações em tempo real de qualquer fonte, incluindo sites, tabelas ou bancos de dados.
Isso garante que, enquanto a fonte de verdade estiver atualizada, o modelo responderá com informações recentes.
Comunique-se em contextos complexos
Outra limitação do uso tradicional de LLMs é a perda de contexto.
LLMs têm dificuldade em manter o contexto em conversas longas ou complexas, o que geralmente resulta em respostas incompletas ou fragmentadas.
Mas um modelo RAG permite consciência de contexto ao buscar informações diretamente de fontes de dados semanticamente relacionadas.
Com informações adicionais voltadas para as necessidades dos usuários – como um chatbot de vendas com catálogo de produtos – o RAG permite que agentes de IA participem de conversas contextuais.
Como funciona o RAG?
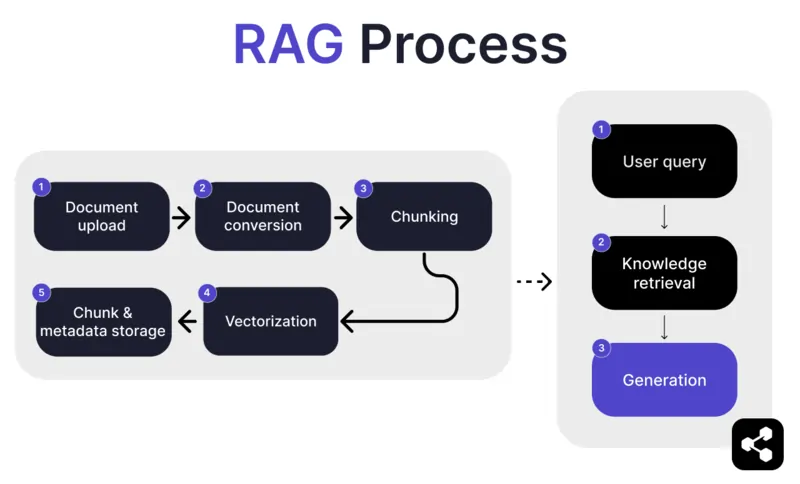
1. Envio de Documento
Primeiro, o criador envia um documento ou arquivo para a biblioteca do agente de IA. O arquivo pode ser uma página da web, PDF ou outro formato compatível, que passa a fazer parte da base de conhecimento da IA.
2. Conversão do Documento
Como existem vários tipos de arquivos – PDFs, páginas da web, etc. – o sistema converte esses arquivos para um formato de texto padronizado, facilitando o processamento e a recuperação de informações relevantes pela IA.
3. Divisão em partes e Armazenamento
O documento convertido é então dividido em partes menores e gerenciáveis, chamadas de chunks. Esses chunks são armazenados em um banco de dados, permitindo que o agente de IA pesquise e recupere de forma eficiente as seções relevantes durante uma consulta.
4. Consulta do Usuário
Após configurar as bases de conhecimento, o usuário pode fazer uma pergunta ao agente de IA. A consulta é processada usando processamento de linguagem natural (PLN) para entender o que o usuário está perguntando.
5. Recuperação do Conhecimento
O agente de IA pesquisa entre os chunks armazenados, usando algoritmos de recuperação para encontrar as informações mais relevantes dos documentos enviados que possam responder à pergunta do usuário.
6. Geração
Por fim, o agente de IA gera uma resposta combinando as informações recuperadas com as capacidades do modelo de linguagem, criando uma resposta coerente e precisa com base na consulta e nos dados recuperados.
Recursos avançados de RAG
Se você não é desenvolvedor, pode se surpreender ao saber que nem todo RAG é igual.
Sistemas diferentes constroem modelos RAG distintos, dependendo da necessidade, do caso de uso ou da habilidade técnica.
Algumas plataformas de IA oferecem recursos avançados de RAG que podem aumentar ainda mais a precisão e confiabilidade do seu software de IA.
Chunking semântico vs chunking ingênuo
Chunking ingênuo é quando um documento é dividido em partes de tamanho fixo, como cortar o texto em trechos de 500 palavras, sem considerar o significado ou contexto.
Chunking semântico, por outro lado, divide o documento em seções significativas com base no conteúdo.
Ele considera divisões naturais, como parágrafos ou tópicos, garantindo que cada bloco contenha uma informação coerente.
Citações obrigatórias
Para setores que automatizam conversas de alto risco com IA – como finanças ou saúde – as citações podem ajudar a gerar confiança nos usuários ao receberem informações.
Desenvolvedores podem configurar seus modelos RAG para fornecer citações para qualquer informação enviada.
Por exemplo, se um funcionário perguntar a um chatbot de IA sobre informações de benefícios de saúde, o chatbot pode responder e fornecer um link para o documento relevante de benefícios do funcionário.
Crie um agente de IA RAG personalizado
Combine o poder dos LLMs mais avançados com o conhecimento exclusivo da sua empresa.
O Botpress é uma plataforma de chatbot de IA flexível e infinitamente extensível.
Ela permite criar qualquer tipo de agente de IA ou chatbot para qualquer finalidade – e oferece o sistema RAG mais avançado do mercado.
Integre seu chatbot a qualquer plataforma ou canal, ou escolha entre nossa biblioteca de integrações prontas. Comece com tutoriais no canal do Botpress no YouTube ou com cursos gratuitos da Botpress Academy.
Comece a construir hoje mesmo. É grátis.
Perguntas frequentes
1. Como o RAG é diferente do ajuste fino de um LLM?
RAG (Geração Aumentada por Recuperação) é diferente do ajuste fino porque o RAG mantém o LLM original inalterado e injeta conhecimento externo em tempo de execução ao recuperar documentos relevantes. O ajuste fino modifica os pesos do modelo usando dados de treinamento, o que exige mais recursos computacionais e precisa ser repetido a cada atualização.
2. Que tipos de fontes de dados não são adequadas para RAG?
Fontes de dados inadequadas para RAG incluem formatos não textuais, como documentos digitalizados, PDFs baseados em imagem, arquivos de áudio sem transcrição e conteúdos desatualizados ou conflitantes. Esses tipos de dados reduzem a precisão do contexto recuperado.
3. Como o RAG se compara a técnicas de aprendizado em contexto, como engenharia de prompts?
O RAG se diferencia da engenharia de prompts ao recuperar conteúdos relevantes de uma base de conhecimento indexada no momento da consulta, em vez de depender de exemplos estáticos e inseridos manualmente no prompt. Isso permite que o RAG seja mais escalável e mantenha o conhecimento atualizado sem necessidade de re-treinamento.
4. Posso usar RAG com LLMs de terceiros, como OpenAI, Anthropic ou Mistral?
Sim, você pode usar RAG com LLMs da OpenAI, Anthropic, Mistral ou outros, gerenciando o pipeline de recuperação de forma independente e enviando o contexto recuperado para o LLM via API. O RAG é independente do modelo, desde que o LLM aceite entrada contextual por meio de prompts.
5. Como é a manutenção contínua de um agente de IA com RAG?
A manutenção contínua de um agente de IA com RAG inclui atualizar a base de conhecimento com documentos novos ou corrigidos, reindexar o conteúdo periodicamente, avaliar a qualidade da recuperação, ajustar o tamanho dos blocos e os métodos de embedding, além de monitorar as respostas do agente para evitar desvios ou alucinações.



