


- O ASR transforma fala em texto usando aprendizado de máquina, permitindo comandos de voz e transcrição em tempo real.
- Os sistemas modernos de ASR migraram de modelos separados de fonemas (HMM-GMM) para modelos de aprendizado profundo que prevêem palavras inteiras.
- O desempenho do ASR é medido pela Taxa de Erro de Palavras (WER), com erros vindos de substituições, deleções ou inserções; WER menor = melhor qualidade de transcrição.
- O futuro do ASR está focado em processamento no próprio dispositivo, para privacidade, e suporte a idiomas com poucos recursos.
Quando foi a última vez que você assistiu algo sem legendas?
Antes elas eram opcionais, mas agora aparecem em vídeos curtos, querendo ou não. As legendas estão tão presentes no conteúdo que você até esquece que existem.
O reconhecimento automático de fala (ASR) — a capacidade de automatizar de forma rápida e precisa a conversão de palavras faladas em texto — é a tecnologia que impulsiona essa mudança.
Quando pensamos em um agente de voz com IA, pensamos na escolha de palavras, na forma de falar e na voz que ele utiliza.
Mas é fácil esquecer que a fluidez das nossas interações depende do bot nos entender. E chegar a esse ponto — o bot te entender mesmo com "ãh" e "éé" em um ambiente barulhento — não foi nada fácil.
Hoje, vamos falar sobre a tecnologia por trás dessas legendas: o reconhecimento automático de fala (ASR).
Deixe-me me apresentar: tenho mestrado em tecnologia da fala e, no meu tempo livre, gosto de acompanhar as novidades em ASR e até criar coisas.
Vou te explicar o básico do ASR, mostrar um pouco da tecnologia por trás e dar um palpite sobre os próximos passos dessa tecnologia.
O que é ASR?
Reconhecimento automático de fala (ASR), ou speech-to-text (STT), é o processo de converter fala em texto escrito usando tecnologia de aprendizado de máquina.
Tecnologias que envolvem fala geralmente integram ASR de alguma forma; pode ser para legendar vídeos, transcrever atendimentos ao cliente para análise ou como parte de uma interação com assistente de voz, entre outros exemplos.
Algoritmos de Reconhecimento de Fala (Speech-to-Text)
As tecnologias por trás mudaram ao longo dos anos, mas todas as versões sempre tiveram dois componentes de alguma forma: dados e um modelo.
No caso do ASR, os dados são fala rotulada – arquivos de áudio de fala e suas respectivas transcrições.
O modelo é o algoritmo usado para prever a transcrição a partir do áudio. Os dados rotulados servem para treinar o modelo, para que ele consiga generalizar em exemplos de fala que nunca viu.
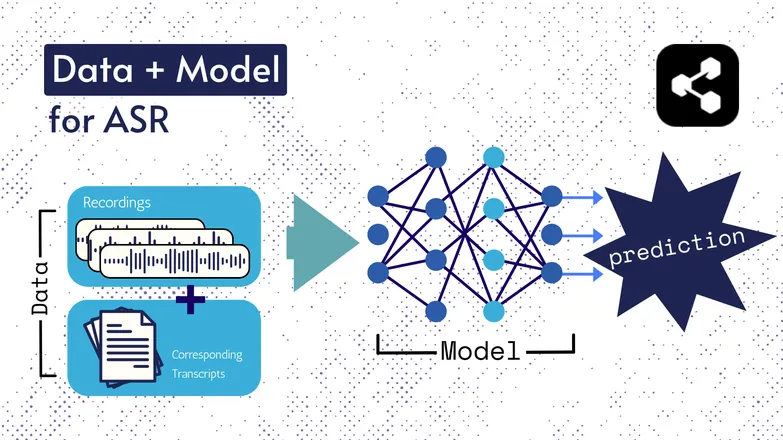
É parecido com como você entende uma sequência de palavras, mesmo que nunca tenha ouvido naquela ordem ou dita por alguém desconhecido.
De novo, os tipos de modelos e seus detalhes mudaram com o tempo, e todos os avanços em velocidade e precisão se devem ao tamanho e às especificações dos conjuntos de dados e dos modelos.
Observação rápida: Extração de Características
Falei sobre características, ou representações no meu artigo sobre texto para fala. Elas são usadas em modelos de ASR antigos e atuais.
A extração de características — transformar fala em características — é o primeiro passo em praticamente todos os fluxos de ASR.
Resumindo, essas características, geralmente espectrogramas, são o resultado de um cálculo matemático feito sobre a fala e transformam a fala em um formato que destaca semelhanças dentro de uma mesma frase e minimiza diferenças entre falantes.
Ou seja, a mesma frase dita por 2 pessoas diferentes terá espectrogramas parecidos, mesmo que as vozes sejam bem diferentes.
Estou destacando isso para avisar que vou falar sobre modelos "prevendo transcrições a partir da fala". Tecnicamente, não é bem assim; os modelos prevêem a partir das características. Mas você pode considerar a extração de características como parte do modelo.
ASR Antigo: HMM-GMM
Modelos ocultos de Markov (HMMs) e modelos de mistura gaussiana (GMMs) são modelos preditivos de antes dos redes neurais profundas dominarem.
Os HMMs dominaram o ASR até pouco tempo atrás.
Dado um arquivo de áudio, o HMM previa a duração de um fonema e o GMM previa qual era o fonema.
Parece invertido, e de certa forma é, tipo:
- HMM: “Os primeiros 0,2 segundos são um fonema.”
- GMM: “Esse fonema é um G, como em Gary.”
Transformar um trecho de áudio em texto exigia alguns componentes extras, como:
- Um dicionário de pronúncia: uma lista completa das palavras do vocabulário, com suas respectivas pronúncias.
- Um modelo de linguagem: combinações de palavras do vocabulário e as probabilidades de aparecerem juntas.
Então, mesmo que o GMM preveja /f/ em vez de /s/, o modelo de linguagem sabe que é muito mais provável que a pessoa tenha dito “um centavo pelos seus pensamentos”, não fensamentos.
Tínhamos todas essas partes porque, sendo direto, nenhuma parte desse processo era realmente boa.
O HMM errava nos alinhamentos, o GMM confundia sons parecidos: /s/ e /f/, /p/ e /t/, e nem vou falar das vogais.
Aí o modelo de linguagem tentava arrumar a bagunça de fonemas incoerentes em algo mais parecido com a língua.
ASR de ponta a ponta com Deep Learning
Muitas partes do fluxo de ASR foram consolidadas desde então.
Em vez de treinar modelos separados para ortografia, alinhamento e pronúncia, um único modelo recebe a fala e gera (com sorte) as palavras corretamente escritas e, hoje em dia, também as marcações de tempo.
(Embora implementações geralmente corrijam ou "reavaliem" esse resultado com um modelo de linguagem adicional.)
Isso não quer dizer que fatores diferentes — como alinhamento e ortografia — não recebam atenção especial. Ainda há muitos estudos focados em corrigir problemas bem específicos.
Ou seja, pesquisadores criam formas de alterar a arquitetura do modelo para atacar fatores específicos do desempenho, como:
- Um decodificador RNN-Transducer condicionado pelas saídas anteriores para melhorar a ortografia.
- Downsampling convolucional para limitar saídas em branco, melhorando o alinhamento.
Eu sei que isso parece complicado. Só estou me adiantando ao meu chefe perguntando “você pode dar um exemplo mais simples?”
A resposta é não.
Não, não posso.
Como o desempenho do ASR é medido?
Quando o ASR erra, você percebe na hora.
Já vi caramelização transcrita como asiáticos comunistas. Crocância virou Cris p — você entendeu.
A métrica que usamos para refletir erros matematicamente é a taxa de erro de palavras (WER). A fórmula do WER é:
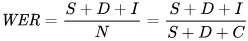
Onde:
- S é o número de substituições (palavras trocadas no texto previsto para coincidir com o texto de referência)
- D é o número de deleções (palavras que faltam na saída, em comparação ao texto de referência)
- I é o número de inserções (palavras a mais na saída, em comparação ao texto de referência)
- N é o número total de palavras no texto de referência
Por exemplo, se o texto de referência é “o gato sentou.”
- Se o modelo gera “o gato afundou”, isso é uma substituição.
- Se o modelo gera “gato sentou”, isso é uma deleção.
- Se o modelo gera “o gato já sentou”, isso é uma inserção.
Quais são as aplicações do ASR?
O ASR é uma ferramenta bem útil.
Também ajudou a melhorar nossa qualidade de vida com mais segurança, acessibilidade e eficiência em setores essenciais.
Saúde
Quando falo para médicos que pesquiso reconhecimento de fala, eles dizem “ah, tipo o Dragon.”
Antes de termos IA generativa na saúde, médicos faziam anotações verbais a 30 palavras por minuto com um vocabulário limitado.
O reconhecimento automático de fala (ASR) tem sido extremamente eficaz para reduzir o esgotamento generalizado entre médicos.
Os médicos equilibram montanhas de papelada com a necessidade de atender seus pacientes. Já em 2018, pesquisadores pediam o uso de transcrição digital em consultas para melhorar a capacidade dos médicos de prestar atendimento.
Isso porque documentar consultas de forma retroativa não só reduz o tempo de contato com o paciente, como também é muito menos preciso do que resumos feitos a partir de transcrições das consultas reais.
Casas Inteligentes
Eu tenho uma piada que sempre faço.
Quando quero apagar as luzes mas não quero levantar, bato palmas duas vezes rapidamente — como se tivesse um interruptor de palmas.
Minha parceira nunca acha graça.
Casas inteligentes ativadas por voz parecem ao mesmo tempo futuristas e um pouco indulgentes demais. Ou pelo menos é o que parece.
Claro, são convenientes, mas em muitos casos permitem fazer coisas que de outra forma não seriam possíveis.
Um ótimo exemplo é o consumo de energia: fazer pequenos ajustes na iluminação e no termostato seria inviável ao longo do dia se você tivesse que levantar e mexer no botão.
A ativação por voz faz com que esses pequenos ajustes sejam não só mais fáceis, mas também interpreta as nuances da fala humana.
Por exemplo, você diz “pode deixar um pouco mais frio?” O assistente usa processamento de linguagem natural para traduzir seu pedido em uma mudança de temperatura, considerando vários outros dados: temperatura atual, previsão do tempo, uso do termostato por outros usuários, etc.
Você faz a parte humana e deixa as tarefas de computador para o computador.
Eu diria que isso é muito mais fácil do que tentar adivinhar quantos graus baixar o aquecedor só pelo seu sentimento.
E é mais eficiente em termos de energia: há relatos de famílias reduzindo o consumo de energia em 80% com iluminação inteligente ativada por voz, para citar um exemplo.
Atendimento ao Cliente
Falamos disso na área da saúde, mas transcrever e resumir é muito mais eficaz do que as pessoas darem resumos retroativos das interações.
De novo, economiza tempo e é mais preciso. O que aprendemos repetidamente é que automações liberam tempo para as pessoas fazerem melhor seu trabalho.
E isso é ainda mais evidente no suporte ao cliente, onde o atendimento impulsionado por ASR tem uma taxa de resolução no primeiro contato 25% maior.
A transcrição e a sumarização ajudam a automatizar o processo de encontrar uma solução com base no sentimento e na solicitação do cliente.
Assistentes Automotivos
Estamos aproveitando o gancho dos assistentes domésticos aqui, mas vale a menção.
O reconhecimento de voz reduz a carga cognitiva e as distrações visuais para motoristas.
E como as distrações são responsáveis por até 30% das colisões, implementar essa tecnologia é uma escolha óbvia para a segurança.
Fonoaudiologia
O ASR já é usado há muito tempo como ferramenta para avaliar e tratar distúrbios da fala.
É importante lembrar que as máquinas não só automatizam tarefas, mas também fazem coisas que humanos não conseguem.
O reconhecimento de fala pode detectar sutilezas na fala que são quase imperceptíveis ao ouvido humano, identificando detalhes da fala afetada que, de outra forma, passariam despercebidos.
O Futuro do ASR
O STT ficou tão bom que nem pensamos mais nisso.
Mas nos bastidores, pesquisadores continuam trabalhando para torná-lo ainda mais poderoso, acessível — e menos perceptível.
Separei algumas tendências empolgantes que aproveitam avanços em ASR e incluí algumas opiniões minhas.
Reconhecimento de Fala no Dispositivo
A maioria das soluções de ASR roda na nuvem. Aposto que você já ouviu isso. Ou seja, o modelo roda em um computador remoto, em outro lugar.
Isso acontece porque o processador do seu celular nem sempre consegue rodar esses modelos enormes, ou demoraria muito para transcrever qualquer coisa.
Em vez disso, seu áudio é enviado pela internet para um servidor remoto com uma GPU pesada demais para caber no bolso. A GPU executa o modelo ASR e devolve a transcrição para o seu dispositivo.
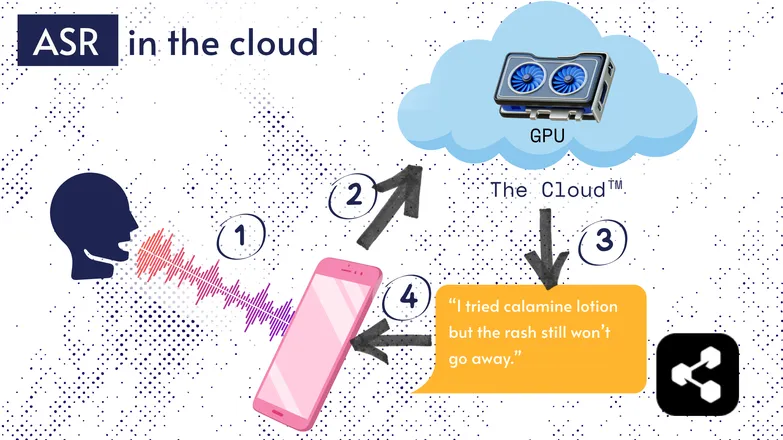
Por questões de eficiência energética e segurança (nem todo mundo quer seus dados pessoais circulando pelo ciberespaço), muita pesquisa tem sido feita para tornar os modelos compactos o suficiente para rodar direto no seu dispositivo, seja um celular, computador ou navegador.
Eu mesmo escrevi uma tese sobre quantização de modelos de ASR para rodarem localmente. A Picovoice é uma empresa canadense que desenvolve IA de voz de baixa latência para rodar no dispositivo, e parece bem interessante.
O ASR no dispositivo torna a transcrição mais acessível e barata, com potencial para atender comunidades de baixa renda.
Interface centrada na transcrição
A distância entre áudio e transcrição está diminuindo. O que isso significa?
Editores de vídeo como Premiere Pro e Descript permitem navegar pelas gravações através da transcrição: clique em uma palavra e você vai direto para o ponto do vídeo.
Precisou gravar algumas vezes? Escolha sua favorita e apague as outras, como em um editor de texto. O vídeo é ajustado automaticamente para você.
Editar assim só com a forma de onda é frustrante, mas com editores baseados em transcrição fica muito fácil.
Da mesma forma, serviços de mensagens como o WhatsApp estão transcrevendo seus áudios e permitindo que você navegue pelo texto. Passe o dedo sobre uma palavra e você vai para aquela parte da gravação.

Curiosidade: eu realmente criei algo parecido com isso cerca de uma semana antes da Apple anunciar um recurso similar.
Esses exemplos mostram como tecnologias complexas nos bastidores trazem simplicidade e intuitividade para o usuário final.
Equidade, Inclusão e Idiomas de Baixo Recurso
A batalha ainda não foi vencida.
O ASR funciona muito bem em inglês e outros idiomas comuns e bem suportados. Isso nem sempre acontece com idiomas de baixo recurso.
Existe uma lacuna para minorias dialetais, fala afetada e outros desafios de equidade em tecnologia de voz.
Desculpe interromper o clima positivo. Esta seção se chama “futuro” do ASR. E eu prefiro olhar para um futuro do qual possamos nos orgulhar.
Se vamos avançar, precisamos fazer isso juntos, ou corremos o risco de aumentar a desigualdade social.
Comece a Usar ASR Hoje
Independentemente do seu negócio, usar ASR é uma escolha óbvia — mas você provavelmente está se perguntando como começar. Como implementar o ASR? Como repassar esses dados para outras ferramentas?
O Botpress oferece cartões de transcrição fáceis de usar. Eles podem ser integrados em um fluxo de arrastar e soltar e ampliados com dezenas de integrações entre aplicativos e canais de comunicação.
Comece a construir hoje. É grátis.
Perguntas frequentes
Quão preciso é o ASR moderno para diferentes sotaques e ambientes barulhentos?
Os sistemas modernos de ASR são impressionantemente precisos para sotaques comuns em idiomas principais, alcançando taxas de erro de palavras (WER) abaixo de 10% em condições ideais, mas a precisão cai consideravelmente com sotaques fortes, dialetos ou muito ruído de fundo. Fornecedores como Google e Microsoft treinam modelos com dados de fala diversos, mas a transcrição perfeita em ambientes barulhentos ainda é um desafio.
O ASR é confiável para transcrever jargões ou termos específicos de setores?
O ASR é menos confiável, por padrão, para jargões ou termos específicos de setores, pois seus dados de treinamento geralmente são voltados para a fala geral; palavras desconhecidas podem ser transcritas incorretamente ou omitidas. No entanto, soluções empresariais permitem vocabulários personalizados, modelos de linguagem específicos e dicionários de pronúncia para melhorar o reconhecimento de termos técnicos em áreas como saúde, direito ou engenharia.
Qual a diferença entre ferramentas gratuitas de ASR e soluções empresariais?
A diferença entre ferramentas gratuitas de ASR e soluções empresariais está na precisão, escalabilidade, personalização e controles de privacidade: ferramentas gratuitas geralmente têm taxas de erro mais altas, suporte limitado a idiomas e restrições de uso, enquanto soluções empresariais oferecem menor WER, personalização por domínio, integrações, SLAs e recursos robustos de segurança para lidar com dados sensíveis.
Como o ASR protege a privacidade do usuário e informações sensíveis durante a transcrição?
O ASR protege a privacidade do usuário por meio de criptografia durante a transmissão dos dados e oferece opções como a execução dos modelos diretamente no dispositivo, evitando o envio do áudio para servidores externos. Muitos provedores corporativos também seguem regulamentações de privacidade como GDPR ou HIPAA e podem anonimizar os dados para proteger informações sensíveis.
Qual é o custo dos serviços de ASR em nuvem em comparação com soluções no dispositivo?
Serviços de ASR na nuvem normalmente cobram por minuto de áudio ou por faixas de uso, com custos variando de US$ 0,03 a mais de US$ 1,00 por minuto, dependendo da precisão e dos recursos, enquanto soluções locais envolvem custos iniciais de desenvolvimento e taxas de licenciamento.


.webp)

