.webp)


- RAG combineert het ophalen van betrouwbare data met LLM-generatie, waardoor AI-antwoorden accuraat, relevant en gebaseerd zijn op echte bedrijfskennis.
- In tegenstelling tot pure LLM’s vermindert RAG hallucinaties door antwoorden te verankeren in specifieke documenten, databases of goedgekeurde content.
- RAG ondersteunt actuele informatie, waardoor AI-systemen vragen kunnen beantwoorden over recente wijzigingen of niche-onderwerpen buiten de statische trainingsdata van een LLM.
- Het onderhouden van een RAG-systeem betekent dat je data up-to-date houdt, de uitkomsten monitort en de retrieval-methodes verfijnt voor optimale prestaties op de lange termijn.
RAG stelt organisaties in staat AI in te zetten – met minder risico dan traditioneel LLM-gebruik.
Retrieval-augmented generation wordt steeds populairder nu meer bedrijven AI-oplossingen introduceren. De eerste enterprise chatbots maakten risicovolle fouten en hadden last van hallucinaties.
RAG stelt bedrijven in staat de kracht van LLM’s te benutten, terwijl de gegenereerde output wordt gebaseerd op hun specifieke bedrijfskennis.
Wat is retrieval-augmented generation?
Retrieval-augmented generation (RAG) in AI is een techniek waarbij a) relevante externe informatie wordt opgehaald en b) AI-gegenereerde antwoorden worden gecombineerd, wat de nauwkeurigheid en relevantie verbetert.
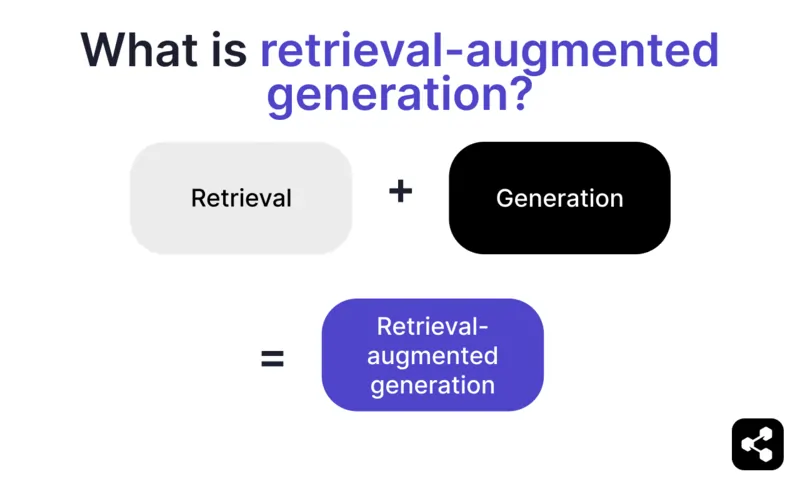
In plaats van alleen te vertrouwen op LLM’s, worden de antwoorden van RAG-modellen gebaseerd op kennisbanken die je zelf bepaalt – zoals de website van een bedrijf of een HR-beleidsdocument.
RAG werkt in twee hoofdstappen:
1. Ophalen
Het model zoekt en haalt relevante data op uit gestructureerde of ongestructureerde bronnen (zoals databases, PDF’s, HTML-bestanden of andere documenten). Deze bronnen kunnen gestructureerd zijn (bijv. tabellen) of ongestructureerd (bijv. goedgekeurde websites).
2. Genereren
Na het ophalen wordt de informatie aan de LLM aangeboden. De LLM gebruikt deze informatie om een natuurlijk klinkend antwoord te genereren, waarbij goedgekeurde data wordt gecombineerd met eigen taalvaardigheid voor accurate, menselijke en merkgetrouwe antwoorden.
Voorbeelden van RAG-toepassingen
Wat is het doel van RAG? Het stelt organisaties in staat relevante, informatieve en accurate output te leveren.
RAG is een directe manier om het risico op onnauwkeurige LLM-uitvoer of hallucinaties te verkleinen.
Voorbeeld 1: Advocatenkantoor
Een advocatenkantoor kan RAG in een AI-systeem gebruiken om:
- Te zoeken naar relevante jurisprudentie, precedenten en rechterlijke uitspraken in documentdatabases tijdens onderzoek.
- Samenvattingen van zaken te genereren door kernfeiten uit dossiers en eerdere uitspraken te halen.
- Medewerkers automatisch te voorzien van relevante updates over regelgeving.
Voorbeeld 2: Makelaarskantoor
Een makelaarskantoor kan RAG in een AI-systeem gebruiken om:
- Data uit vastgoedtransactiegeschiedenissen en misdaadstatistieken van buurten samen te vatten.
- Juridische vragen over vastgoedtransacties te beantwoorden door lokale wet- en regelgeving te citeren.
- Taxatieprocessen te stroomlijnen door gegevens uit rapporten over de staat van het pand, markttrends en historische verkopen te halen.
Voorbeeld 3: E-commercewinkel
Een e-commercebedrijf kan RAG in een AI-systeem gebruiken om:
- Productinformatie, specificaties en reviews uit de bedrijfsdatabase te verzamelen voor gepersonaliseerde productaanbevelingen.
- Bestelgeschiedenis op te halen om gepersonaliseerde winkelervaringen te creëren die aansluiten bij de voorkeuren van de gebruiker.
- Gerichte e-mailcampagnes te genereren door klantsegmentatiegegevens op te halen en te combineren met recente aankooppatronen.
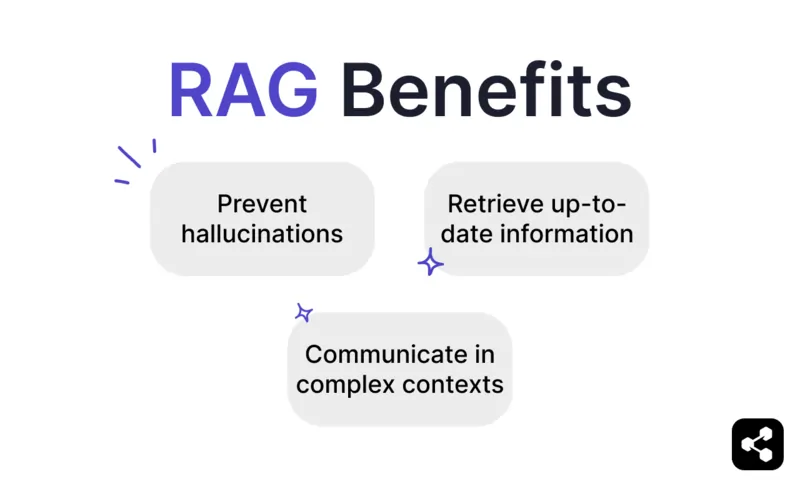
Voordelen van RAG
Iedereen die ChatGPT of Claude heeft gebruikt, weet dat LLM’s minimale ingebouwde waarborgen hebben.
Zonder goede controle kunnen ze onnauwkeurige of zelfs schadelijke informatie produceren, waardoor ze onbetrouwbaar zijn voor gebruik in de praktijk.
RAG biedt een oplossing door antwoorden te baseren op betrouwbare, actuele databronnen en zo deze risico’s aanzienlijk te verkleinen.
Voorkom hallucinaties en onnauwkeurigheden
Traditionele taalmodellen genereren vaak hallucinaties — antwoorden die overtuigend klinken, maar feitelijk onjuist of irrelevant zijn.
RAG beperkt hallucinaties door antwoorden te baseren op betrouwbare en zeer relevante databronnen.
De retrieval-stap zorgt ervoor dat het model verwijst naar accurate, actuele informatie, wat de kans op hallucinaties aanzienlijk verkleint en de betrouwbaarheid vergroot.
Haal actuele informatie op
Hoewel LLM’s krachtig zijn voor veel taken, kunnen ze geen accurate informatie geven over zeldzame of recente onderwerpen – waaronder specifieke bedrijfskennis.
Maar met RAG kan het model realtime informatie ophalen uit elke bron, zoals websites, tabellen of databases.
Dit zorgt ervoor dat, zolang de bron van waarheid wordt bijgewerkt, het model altijd met actuele informatie reageert.
Communiceer in complexe contexten
Een ander zwak punt van traditioneel LLM-gebruik is het verlies van contextuele informatie.
LLM’s hebben moeite om context vast te houden in lange of complexe gesprekken. Dit leidt vaak tot onvolledige of gefragmenteerde antwoorden.
Maar een RAG-model maakt contextbewustzijn mogelijk door direct informatie te halen uit semantisch gekoppelde databronnen.
Met extra informatie die specifiek is afgestemd op de behoeften van de gebruiker – zoals een sales-chatbot met een productcatalogus – kunnen AI-agenten met RAG deelnemen aan contextuele gesprekken.
Hoe werkt RAG?
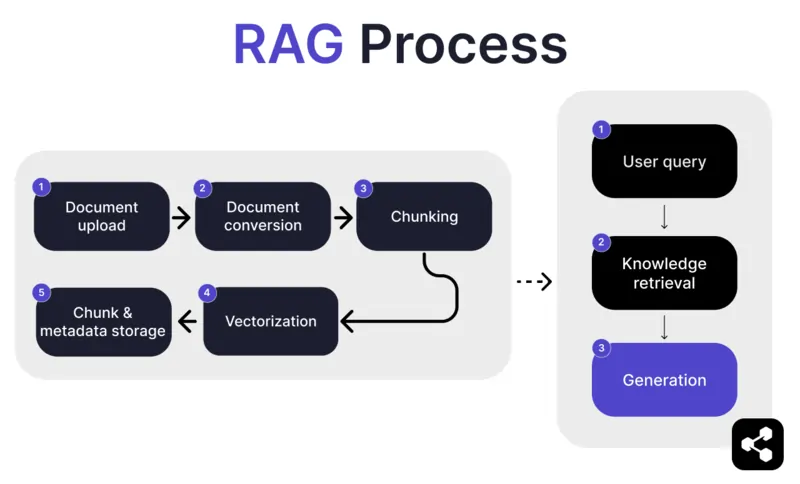
1. Document uploaden
Eerst uploadt de bouwer een document of bestand naar de bibliotheek van de AI-agent. Het bestand kan een webpagina, PDF of een ander ondersteund formaat zijn en vormt een deel van de kennisbasis van de AI.
2. Documentconversie
Omdat er veel verschillende bestandstypen zijn – PDF’s, webpagina’s, enzovoort – zet het systeem deze bestanden om naar een gestandaardiseerd tekstformaat, zodat de AI ze makkelijker kan verwerken en relevante informatie kan ophalen.
3. Opsplitsen en opslaan
Het geconverteerde document wordt vervolgens opgedeeld in kleinere, beheersbare stukken, ofwel ‘chunks’. Deze stukken worden opgeslagen in een database, zodat de AI-agent efficiënt relevante secties kan zoeken en ophalen tijdens een vraag.
4. Gebruikersvraag
Nadat de kennisbanken zijn ingericht, kan een gebruiker de AI-agent een vraag stellen. De vraag wordt verwerkt met behulp van natural language processing (NLP) om te begrijpen wat de gebruiker bedoelt.
5. Kennis ophalen
De AI-agent doorzoekt de opgeslagen stukken met retrieval-algoritmen om de meest relevante informatie uit de geüploade documenten te vinden die de vraag van de gebruiker kan beantwoorden.
6. Genereren
Tot slot genereert de AI-agent een antwoord door de opgehaalde informatie te combineren met de mogelijkheden van het taalmodel, zodat er een samenhangend en contextueel juist antwoord ontstaat op basis van de vraag en de gevonden data.
Geavanceerde RAG-functionaliteiten
Als je geen ontwikkelaar bent, is het misschien verrassend dat niet elke RAG hetzelfde is.
Verschillende systemen bouwen verschillende RAG-modellen, afhankelijk van hun behoeften, toepassing of vaardigheden.
Sommige AI-platforms bieden geavanceerde RAG-functionaliteiten die de nauwkeurigheid en betrouwbaarheid van je AI-software verder kunnen verbeteren.
Semantisch vs naïef opsplitsen
Naïef opsplitsen betekent dat een document wordt verdeeld in stukken van vaste grootte, bijvoorbeeld tekstblokken van 500 woorden, ongeacht betekenis of context.
Semantisch opsplitsen daarentegen verdeelt het document in betekenisvolle secties op basis van de inhoud.
Het houdt rekening met natuurlijke onderbrekingen, zoals alinea’s of onderwerpen, zodat elk deel een samenhangend stuk informatie bevat.
Verplichte bronvermelding
Voor sectoren die risicovolle gesprekken automatiseren met AI – zoals financiën of zorg – kunnen bronvermeldingen het vertrouwen van gebruikers vergroten.
Ontwikkelaars kunnen hun RAG-modellen instrueren om bij elke verstuurde informatie een bronvermelding te geven.
Als een medewerker bijvoorbeeld een AI-chatbot vraagt naar informatie over arbeidsvoorwaarden, kan de chatbot antwoorden en een link geven naar het relevante document over personeelsvoordelen.
Bouw een eigen RAG AI-agent
Combineer de kracht van de nieuwste LLM’s met je unieke bedrijfskennis.
Botpress is een flexibel en eindeloos uitbreidbaar AI-chatbotplatform.
Het stelt gebruikers in staat elk type AI-agent of chatbot te bouwen voor elke toepassing – en biedt het meest geavanceerde RAG-systeem op de markt.
Integreer je chatbot met elk platform of kanaal, of kies uit onze bibliotheek met kant-en-klare integraties. Begin met tutorials van het Botpress YouTube-kanaal of met gratis cursussen van Botpress Academy.
Begin vandaag nog met bouwen. Het is gratis.
Veelgestelde vragen
1. Hoe verschilt RAG van het fijnafstemmen van een LLM?
RAG (Retrieval-Augmented Generation) verschilt van fine-tuning omdat RAG het oorspronkelijke LLM ongemoeid laat en externe kennis toevoegt tijdens het uitvoeren door relevante documenten op te halen. Fine-tuning past de gewichten van het model aan met trainingsdata, wat meer rekenkracht vereist en bij elke update opnieuw moet gebeuren.
2. Welke soorten databronnen zijn niet geschikt voor RAG?
Databronnen die niet geschikt zijn voor RAG zijn onder andere niet-tekstuele formaten zoals gescande documenten, PDF's op basis van afbeeldingen, audiobestanden zonder transcriptie en verouderde of tegenstrijdige inhoud. Dit soort data vermindert de nauwkeurigheid van de opgehaalde context.
3. Hoe verhoudt RAG zich tot in-context learning-technieken zoals prompt engineering?
RAG verschilt van prompt engineering doordat het relevante inhoud ophaalt uit een grote, geïndexeerde kennisbank op het moment van de vraag, in plaats van te vertrouwen op statische, handmatig ingevoegde voorbeelden in de prompt. Hierdoor kan RAG beter opschalen en actuele kennis behouden zonder het model opnieuw te trainen.
4. Kan ik RAG gebruiken met externe LLM's zoals OpenAI, Anthropic of Mistral?
Ja, je kunt RAG gebruiken met LLM's van OpenAI, Anthropic, Mistral of anderen door de retrieval-pijplijn los te beheren en de opgehaalde context via de API naar het LLM te sturen. RAG is model-onafhankelijk zolang het LLM contextuele input via prompts ondersteunt.
5. Hoe ziet het doorlopend onderhoud eruit voor een AI-agent met RAG?
Doorlopend onderhoud voor een AI-agent met RAG bestaat uit het bijwerken van de kennisbank met nieuwe of gecorrigeerde documenten, het periodiek opnieuw indexeren van inhoud, het evalueren van de kwaliteit van de retrieval, het afstemmen van chunkgrootte en embedding-methoden, en het monitoren van de reacties van de agent op afwijkingen of hallucinaties.



