.webp)


- RAG menggabungkan pengambilan data dari sumber tepercaya dengan generasi LLM, memastikan respons AI akurat, relevan, dan didasarkan pada pengetahuan bisnis nyata.
- Berbeda dengan LLM murni, RAG mengurangi halusinasi dengan mendasarkan jawaban pada dokumen, basis data, atau konten yang telah disetujui.
- RAG mendukung informasi terkini, memungkinkan sistem AI menjawab pertanyaan tentang perubahan terbaru atau topik khusus di luar data pelatihan statis LLM.
- Memelihara sistem RAG melibatkan pembaruan data secara berkala, memantau hasil, dan menyempurnakan metode pengambilan data untuk performa terbaik seiring waktu.
RAG memungkinkan organisasi memanfaatkan AI – dengan risiko lebih rendah dibandingkan penggunaan LLM tradisional.
Retrieval-augmented generation semakin populer seiring banyak bisnis mulai mengadopsi solusi AI. Chatbot perusahaan generasi awal sering mengalami kesalahan dan halusinasi yang berisiko.
RAG memungkinkan perusahaan memanfaatkan kekuatan LLM sambil memastikan hasil yang dihasilkan tetap sesuai dengan pengetahuan bisnis mereka sendiri.
Apa itu retrieval-augmented generation?
Retrieval-augmented generation (RAG) dalam AI adalah teknik yang menggabungkan a) pengambilan informasi eksternal yang relevan dan b) respons yang dihasilkan AI, sehingga meningkatkan akurasi dan relevansi.
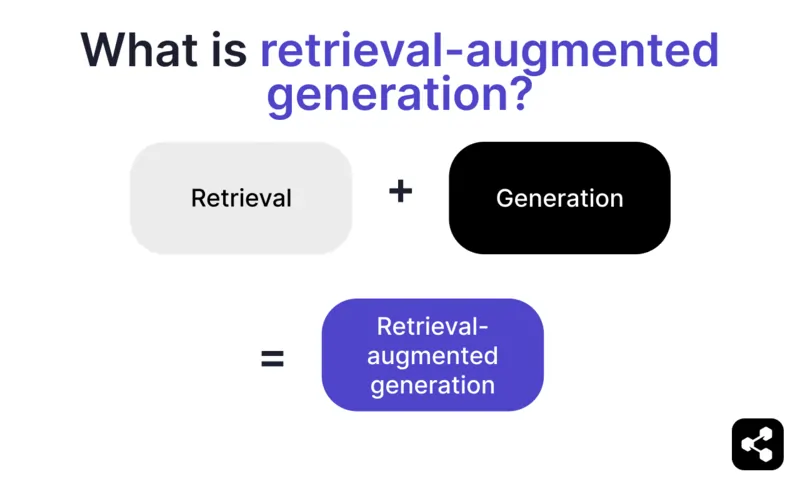
Alih-alih hanya mengandalkan hasil dari large language models (LLM), respons dari model RAG didasarkan pada basis pengetahuan yang ditentukan oleh pembuat agen AI – seperti halaman web perusahaan atau dokumen kebijakan HR.
RAG bekerja dalam dua langkah utama:
1. Pengambilan Data
Model mencari dan mengambil data relevan dari sumber terstruktur atau tidak terstruktur (misalnya basis data, PDF, file HTML, atau dokumen lain). Sumber ini bisa berupa data terstruktur (misalnya tabel) atau tidak terstruktur (misalnya situs web yang disetujui).
2. Generasi
Setelah pengambilan data, informasi dimasukkan ke dalam LLM. LLM menggunakan informasi tersebut untuk menghasilkan respons dalam bahasa alami, menggabungkan data yang telah disetujui dengan kemampuannya sendiri untuk menciptakan jawaban yang akurat, alami, dan sesuai merek.
Contoh Penggunaan RAG
Apa tujuan RAG? RAG memungkinkan organisasi memberikan output yang relevan, informatif, dan akurat.
RAG adalah cara langsung untuk mengurangi risiko keluaran LLM yang tidak akurat atau halusinasi.
Contoh 1: Firma Hukum
Sebuah firma hukum dapat menggunakan RAG dalam sistem AI untuk:
- Mencari yurisprudensi, preseden, dan putusan hukum yang relevan dari basis data dokumen saat melakukan riset.
- Membuat ringkasan kasus dengan mengekstrak fakta penting dari berkas kasus dan putusan sebelumnya.
- Secara otomatis memberikan pembaruan regulasi yang relevan kepada karyawan.
Contoh 2: Agen Properti
Sebuah agen properti dapat menggunakan RAG dalam sistem AI untuk:
- Merangkum data dari riwayat transaksi properti dan statistik kejahatan di lingkungan sekitar.
- Menjawab pertanyaan hukum tentang transaksi properti dengan mengutip undang-undang dan regulasi properti setempat.
- Mempercepat proses penilaian dengan mengambil data dari laporan kondisi properti, tren pasar, dan penjualan sebelumnya.
Contoh 3: Toko E-Commerce
Sebuah toko e-commerce dapat menggunakan RAG dalam sistem AI untuk:
- Mengumpulkan informasi produk, spesifikasi, dan ulasan dari basis data perusahaan untuk memberikan rekomendasi produk yang dipersonalisasi.
- Mengambil riwayat pesanan untuk menciptakan pengalaman belanja yang disesuaikan dengan preferensi pengguna.
- Membuat kampanye email tertarget dengan mengambil data segmentasi pelanggan dan menggabungkannya dengan pola pembelian terbaru.
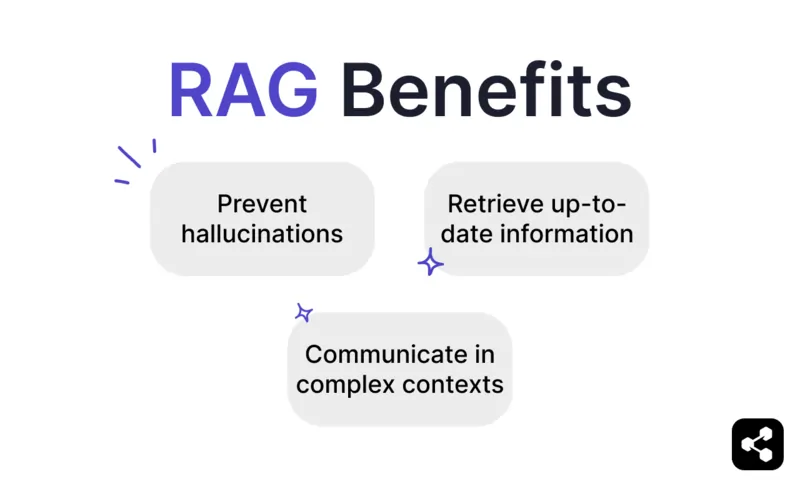
Manfaat RAG
Seperti yang diketahui siapa pun yang pernah menggunakan ChatGPT atau Claude, LLM memiliki perlindungan minimal bawaan.
Tanpa pengawasan yang tepat, mereka dapat menghasilkan informasi yang tidak akurat atau bahkan berbahaya, sehingga membuatnya tidak dapat diandalkan untuk penerapan di dunia nyata.
RAG menawarkan solusi dengan mendasarkan respons pada sumber data tepercaya dan terbaru, sehingga risiko tersebut berkurang secara signifikan.
Mencegah halusinasi dan ketidakakuratan
Model bahasa tradisional sering menghasilkan halusinasi — jawaban yang terdengar meyakinkan namun sebenarnya salah atau tidak relevan.
RAG mengurangi halusinasi dengan mendasarkan respons pada sumber data yang andal dan sangat relevan.
Langkah pengambilan data memastikan model merujuk pada informasi yang akurat dan terbaru, sehingga kemungkinan halusinasi berkurang dan keandalan meningkat.
Mengambil informasi terbaru
Meskipun LLM sangat berguna untuk banyak tugas, mereka tidak dapat memberikan informasi akurat tentang hal-hal langka atau terbaru – termasuk pengetahuan bisnis khusus.
Namun RAG memungkinkan model mengambil informasi real-time dari sumber mana pun, termasuk situs web, tabel, atau basis data.
Ini memastikan bahwa selama sumber kebenaran diperbarui, model akan memberikan informasi yang terbaru.
Berkomunikasi dalam konteks yang kompleks
Kelemahan lain dari penggunaan LLM tradisional adalah hilangnya informasi kontekstual.
LLM kesulitan mempertahankan konteks dalam percakapan yang panjang atau rumit. Hal ini sering menyebabkan jawaban yang tidak lengkap atau terputus-putus.
Namun model RAG memungkinkan pemahaman konteks dengan mengambil informasi langsung dari sumber data yang terhubung secara semantik.
Dengan informasi tambahan yang ditujukan khusus untuk kebutuhan pengguna – seperti chatbot penjualan yang dilengkapi katalog produk – RAG memungkinkan agen AI berpartisipasi dalam percakapan kontekstual.
Bagaimana cara kerja RAG?
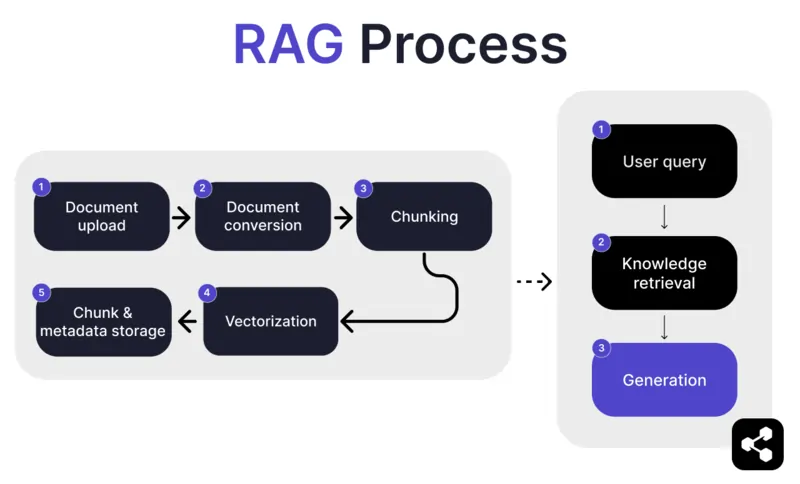
1. Unggah Dokumen
Pertama, pembuat mengunggah dokumen atau file ke perpustakaan agen AI mereka. File ini bisa berupa halaman web, PDF, atau format lain yang didukung, yang membentuk bagian dari basis pengetahuan AI.
2. Konversi Dokumen
Karena ada banyak jenis file – PDF, halaman web, dan sebagainya – sistem akan mengonversi file-file ini ke format teks standar agar lebih mudah diproses AI dan diambil informasinya.
3. Pemecahan dan Penyimpanan
Dokumen yang telah dikonversi kemudian dipecah menjadi bagian-bagian kecil yang mudah dikelola, atau disebut chunk. Chunk ini disimpan dalam basis data, sehingga agen AI dapat mencari dan mengambil bagian yang relevan secara efisien saat ada pertanyaan.
4. Pertanyaan Pengguna
Setelah basis pengetahuan siap, pengguna dapat mengajukan pertanyaan kepada agen AI. Pertanyaan ini diproses menggunakan natural language processing (NLP) untuk memahami maksud pengguna.
5. Pengambilan Pengetahuan
Agen AI mencari di antara chunk yang tersimpan, menggunakan algoritma pengambilan data untuk menemukan bagian informasi paling relevan dari dokumen yang diunggah yang dapat menjawab pertanyaan pengguna.
6. Generasi
Terakhir, agen AI akan menghasilkan jawaban dengan menggabungkan informasi yang diambil dengan kemampuan model bahasanya, sehingga menghasilkan respons yang koheren dan akurat sesuai konteks berdasarkan pertanyaan dan data yang diambil.
Fitur RAG Lanjutan
Jika Anda bukan pengembang, Anda mungkin terkejut mengetahui bahwa tidak semua RAG itu sama.
Setiap sistem akan membangun model RAG yang berbeda, tergantung kebutuhan, kasus penggunaan, atau kemampuan teknisnya.
Beberapa platform AI menawarkan fitur RAG lanjutan yang dapat meningkatkan akurasi dan keandalan perangkat lunak AI Anda.
Chunking semantik vs chunking naif
Chunking naif adalah ketika dokumen dipecah menjadi bagian-bagian berukuran tetap, seperti memotong teks menjadi 500 kata per bagian, tanpa memperhatikan makna atau konteks.
Chunking semantik, sebaliknya, memecah dokumen menjadi bagian-bagian bermakna berdasarkan isi.
Metode ini mempertimbangkan jeda alami, seperti paragraf atau topik, sehingga setiap chunk berisi informasi yang utuh.
Kutipan wajib
Untuk industri yang mengotomatisasi percakapan berisiko tinggi dengan AI – seperti keuangan atau kesehatan – sumber dapat membantu membangun kepercayaan pengguna saat menerima informasi.
Pengembang dapat menginstruksikan model RAG mereka untuk selalu menyertakan sumber pada setiap informasi yang diberikan.
Misalnya, jika karyawan meminta chatbot AI informasi tentang tunjangan kesehatan, chatbot dapat menjawab sekaligus memberikan tautan ke dokumen tunjangan karyawan terkait.
Bangun Agen AI RAG Kustom
Gabungkan kekuatan LLM terbaru dengan pengetahuan unik perusahaan Anda.
Botpress adalah platform chatbot AI yang fleksibel dan dapat diperluas tanpa batas.
Platform ini memungkinkan pengguna membangun agen AI atau chatbot untuk berbagai kebutuhan – dan menawarkan sistem RAG paling canggih di pasar.
Integrasikan chatbot Anda ke platform atau saluran apa pun, atau pilih dari pustaka integrasi siap pakai kami. Mulailah dengan tutorial dari channel YouTube Botpress atau kursus gratis dari Botpress Academy.
Mulai membangun hari ini. Gratis.
FAQ
1. Apa perbedaan RAG dengan fine-tuning pada LLM?
RAG (Retrieval-Augmented Generation) berbeda dari fine-tuning karena RAG menjaga LLM asli tetap tidak berubah dan memasukkan pengetahuan eksternal secara langsung saat dijalankan dengan mengambil dokumen yang relevan. Fine-tuning mengubah bobot model menggunakan data pelatihan, yang membutuhkan lebih banyak komputasi dan harus diulang setiap kali ada pembaruan.
2. Jenis sumber data apa saja yang tidak cocok untuk RAG?
Sumber data yang tidak cocok untuk RAG meliputi format non-teks seperti dokumen hasil scan, PDF berbasis gambar, file audio tanpa transkrip, serta konten yang sudah usang atau saling bertentangan. Jenis data seperti ini dapat mengurangi akurasi konteks yang diambil.
3. Bagaimana perbandingan RAG dengan teknik in-context learning seperti prompt engineering?
RAG berbeda dari prompt engineering karena mengambil konten relevan dari basis pengetahuan besar yang diindeks saat ada pertanyaan, bukan mengandalkan contoh statis yang dimasukkan secara manual ke dalam prompt. Ini membuat RAG lebih mudah diskalakan dan dapat mempertahankan pengetahuan terbaru tanpa perlu pelatihan ulang.
4. Apakah saya bisa menggunakan RAG dengan LLM pihak ketiga seperti OpenAI, Anthropic, atau Mistral?
Ya, Anda dapat menggunakan RAG dengan LLM dari OpenAI, Anthropic, Mistral, atau lainnya dengan mengelola proses pengambilan data secara terpisah dan mengirimkan konteks yang diambil ke LLM melalui API-nya. RAG bersifat agnostik terhadap model selama LLM mendukung penerimaan input kontekstual melalui prompt.
5. Seperti apa pemeliharaan berkelanjutan untuk agen AI yang menggunakan RAG?
Pemeliharaan berkelanjutan untuk agen AI berbasis RAG meliputi memperbarui basis pengetahuan dengan dokumen baru atau yang telah dikoreksi, melakukan re-indeksasi konten secara berkala, mengevaluasi kualitas pengambilan data, menyesuaikan ukuran potongan dan metode embedding, serta memantau respons agen untuk mendeteksi masalah pergeseran atau halusinasi.



