


- Deep neural network (DNN) adalah sistem machine learning yang terdiri dari lapisan-lapisan node terhubung yang mempelajari pola dalam data untuk membuat prediksi.
- DNN dapat menyesuaikan koneksi internalnya berdasarkan kesalahan sebelumnya, sehingga akurasinya meningkat seiring waktu melalui proses backpropagation.
- Kemajuan daya komputasi dan ketersediaan dataset besar telah membuat DNN menjadi solusi praktis untuk tugas-tugas yang melibatkan data tidak terstruktur seperti teks, gambar, dan audio.
- DNN bekerja seperti “kotak hitam” di mana seringkali tidak jelas bagaimana keputusan diambil.
Apa itu deep neural network?
Deep neural network (DNN) adalah jenis model machine learning yang meniru cara otak manusia memproses informasi. Berbeda dengan algoritma tradisional yang mengikuti aturan tetap, DNN dapat mempelajari pola dari data dan membuat prediksi berdasarkan pengalaman sebelumnya — persis seperti manusia.
DNN adalah dasar dari deep learning, yang mendukung aplikasi seperti agen AI, pengenalan gambar, asisten suara, chatbot AI.
Pasar AI global—termasuk aplikasi yang didukung oleh deep neural network—akan melampaui $500 miliar pada tahun 2027.
Apa itu arsitektur neural network?
Kata “deep” pada DNN mengacu pada banyaknya lapisan tersembunyi, yang memungkinkan jaringan mengenali pola-pola yang kompleks.
Neural network terdiri dari beberapa lapisan node yang menerima input dari lapisan lain dan menghasilkan output hingga hasil akhir tercapai.
Neural network terdiri dari lapisan-lapisan node (neuron). Setiap node menerima input, memprosesnya, lalu meneruskannya ke lapisan berikutnya.
- Lapisan input: Lapisan pertama yang menerima data mentah (misalnya gambar, teks).
- Lapisan tersembunyi: Lapisan di antara input dan output yang mengubah data dan mendeteksi pola.
- Lapisan output: Menghasilkan prediksi akhir.
Neural network dapat memiliki jumlah lapisan tersembunyi berapa pun: semakin banyak lapisan node dalam jaringan, semakin tinggi kompleksitasnya. Neural network tradisional biasanya terdiri dari 2 atau 3 lapisan tersembunyi, sedangkan jaringan deep learning bisa memiliki hingga 150 lapisan tersembunyi.
Apa perbedaan neural network dan deep neural network?
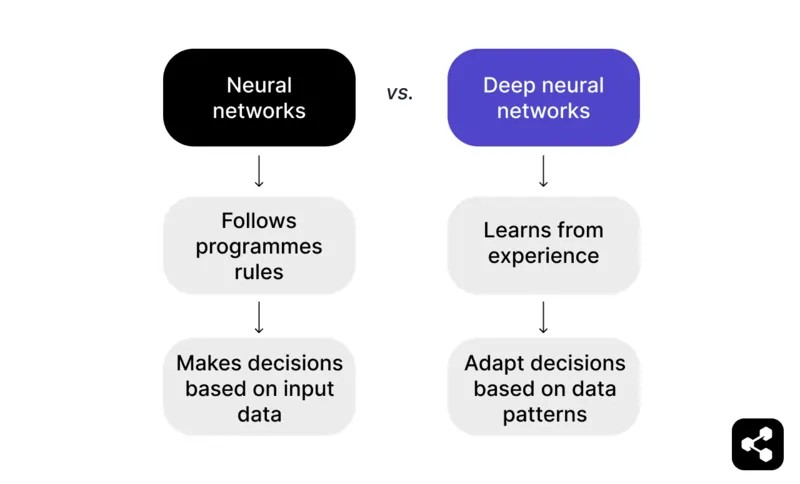
Singkatnya: Neural network yang mampu melampaui data input dan belajar dari pengalaman sebelumnya menjadi deep neural network.
Neural network mengikuti aturan yang diprogram untuk mengambil keputusan berdasarkan data input. Misalnya, dalam permainan catur, neural network dapat menyarankan langkah berdasarkan taktik dan strategi yang sudah ditentukan, namun terbatas pada apa yang diberikan oleh programmer.
Namun deep neural network melangkah lebih jauh dengan belajar dari pengalaman. Alih-alih hanya mengandalkan aturan yang sudah ada, DNN dapat menyesuaikan keputusannya berdasarkan pola yang dikenali dari dataset besar.
Contoh
Bayangkan Anda membuat program untuk mengenali anjing dalam foto. Neural network tradisional memerlukan aturan eksplisit untuk mengidentifikasi ciri seperti bulu atau ekor. Sebaliknya, DNN akan belajar dari ribuan gambar berlabel dan meningkatkan akurasinya seiring waktu — bahkan untuk kasus sulit tanpa perlu pemrograman tambahan.
Bagaimana cara kerja deep neural network?
Pertama, setiap neuron di lapisan input menerima bagian data mentah, seperti piksel dari gambar atau kata dari kalimat, dan memberikan bobot pada input tersebut, menandakan seberapa relevan data itu untuk tugas yang sedang dijalankan.
Bobot rendah (kurang dari 0,5) berarti informasi tersebut kurang relevan. Input berbobot ini diteruskan ke lapisan tersembunyi, di mana neuron menyesuaikan informasi lebih lanjut. Proses ini berlanjut di beberapa lapisan hingga lapisan output menghasilkan prediksi akhir.
Bagaimana deep neural network mengetahui apakah hasilnya benar?
Deep neural network mengetahui kebenaran prediksinya dengan membandingkan hasil prediksi dengan data berlabel selama pelatihan. Untuk setiap input, jaringan memeriksa apakah prediksinya sesuai dengan hasil sebenarnya. Jika salah, jaringan menghitung kesalahan menggunakan loss function, yang mengukur seberapa jauh prediksi dari kenyataan.
Jaringan kemudian menggunakan backpropagation untuk menyesuaikan bobot neuron yang berkontribusi pada kesalahan tersebut. Proses ini diulang pada setiap iterasi.
Apa saja jenis-jenis neural network?
Bagaimana deep neural network berkembang seiring waktu?
Deep neural network berkembang seiring waktu dengan belajar dari kesalahan. Saat membuat prediksi—misalnya mengidentifikasi masalah pelanggan atau merekomendasikan produk—jaringan memeriksa apakah hasilnya benar. Jika tidak, sistem menyesuaikan diri agar lebih baik di kesempatan berikutnya.
Contohnya, dalam dukungan pelanggan, DNN bisa memprediksi cara menyelesaikan tiket. Jika prediksinya salah, ia belajar dari kesalahan itu dan menjadi lebih baik dalam menyelesaikan tiket serupa di masa depan. Dalam penjualan, DNN dapat mempelajari prospek mana yang paling berpotensi dengan menganalisis transaksi sebelumnya, sehingga rekomendasinya semakin akurat.
Jadi, dengan setiap interaksi, DNN menjadi semakin akurat dan andal.
Apakah deep neural network berpikir berbeda dari manusia?
Namun model deep learning sering berfungsi sebagai 'kotak hitam', artinya manusia sulit memahami bagaimana keputusan diambil. Seperti yang dijelaskan peneliti AI Cynthia Rudin dari Duke University , interpretabilitas sangat penting untuk penerapan AI yang etis, terutama di lingkungan berisiko tinggi.
Para peneliti telah mencoba memvisualisasikan bagaimana jaringan memproses gambar, namun untuk tugas yang lebih kompleks—seperti bahasa atau prediksi keuangan—logikanya tetap tersembunyi. Walaupun algoritma ini terasa baru, banyak yang dikembangkan puluhan tahun lalu. Kemajuan data dan daya komputasi lah yang membuatnya kini dapat digunakan secara praktis.
Mengapa deep neural network semakin populer?
1. Peningkatan daya pemrosesan
Salah satu alasan utama meningkatnya penggunaan DNN adalah daya pemrosesan yang kini lebih cepat dan murah. Kemampuan komputasi sangat berpengaruh dalam mencapai konvergensi yang cepat. “Munculnya perangkat keras khusus seperti Graphics Processing Units (GPU) dan Tensor Processing Units (TPU) membuat pelatihan jaringan dengan miliaran parameter menjadi mungkin.”
2. Ketersediaan dataset yang semakin banyak
Faktor penting lainnya adalah ketersediaan dataset besar, yang sangat dibutuhkan deep neural network untuk belajar secara efektif. Seiring bisnis menghasilkan lebih banyak data, DNN dapat menemukan pola kompleks yang tidak dapat ditangani model tradisional.
3. Kemampuan memproses data tidak terstruktur yang semakin baik
Kemampuan mereka dalam memproses data tidak terstruktur seperti teks, gambar, dan audio juga membuka aplikasi baru di bidang seperti chatbot, sistem rekomendasi, dan analitik prediktif.
Apakah neural network bisa bekerja dengan data tidak terstruktur?
Ya, neural network dapat bekerja dengan data tidak terstruktur, dan ini adalah salah satu keunggulan terbesarnya.
Artificial neural network yang bekerja dengan data tidak terstruktur biasanya menggunakan unsupervised learning.
Algoritma machine learning tradisional kesulitan memproses data tidak terstruktur karena membutuhkan rekayasa fitur—yaitu pemilihan dan ekstraksi fitur yang relevan secara manual. Sebaliknya, jaringan saraf dapat secara otomatis mempelajari pola dari data mentah tanpa banyak intervensi manual.
Bagaimana jaringan saraf dalam belajar melalui pelatihan?
Jaringan saraf dalam belajar dengan membuat prediksi dan membandingkannya dengan hasil yang benar. Misalnya, saat memproses foto, jaringan ini memprediksi apakah sebuah gambar berisi anjing dan mencatat seberapa sering prediksinya benar.
Jaringan menghitung akurasinya dengan memeriksa persentase prediksi yang benar dan menggunakan umpan balik ini untuk memperbaiki diri. Ia menyesuaikan bobot neuron-neuronnya dan menjalankan prosesnya lagi. Jika akurasi meningkat, bobot baru dipertahankan; jika tidak, dilakukan penyesuaian lain.
Siklus ini diulang berkali-kali hingga jaringan dapat mengenali pola dan membuat prediksi yang akurat secara konsisten. Setelah mencapai titik ini, jaringan dianggap telah konvergen dan berhasil dilatih.
Hemat waktu pengkodean dengan hasil yang lebih baik
Jaringan saraf dinamakan demikian karena pendekatan pemrograman ini mirip dengan cara kerja otak.
Sama seperti otak, algoritma jaringan saraf menggunakan jaringan neuron atau node. Dan seperti otak, neuron-neuron ini adalah fungsi diskrit (atau mesin kecil, jika Anda mau) yang menerima input dan menghasilkan output. Node-node ini disusun dalam lapisan, di mana output dari neuron pada satu lapisan menjadi input bagi neuron di lapisan berikutnya, hingga neuron pada lapisan terluar menghasilkan hasil akhir.
Jadi, terdapat beberapa lapisan neuron, di mana setiap neuron menerima input terbatas dan menghasilkan output terbatas, mirip dengan otak. Lapisan pertama (atau lapisan input) menerima masukan, dan lapisan terakhir (atau lapisan output) menghasilkan hasil akhir dari jaringan.
Apakah tepat menyebut algoritma ini sebagai “jaringan saraf”?
Menyebut algoritma ini sebagai 'jaringan saraf dalam' terbukti efektif secara branding, meski bisa menimbulkan ekspektasi yang terlalu tinggi. Walaupun kuat, model-model ini masih jauh lebih sederhana dibandingkan kompleksitas otak manusia. Namun demikian, para peneliti terus mengeksplorasi arsitektur jaringan saraf untuk mencapai kecerdasan umum yang menyerupai manusia.
Meski begitu, ada juga yang mencoba merekayasa ulang otak dengan menggunakan jaringan saraf yang sangat kompleks, dengan harapan dapat mereplikasi kecerdasan umum seperti manusia dalam pengembangan bot. Lalu, bagaimana jaringan saraf dan teknik machine learning membantu kita dalam masalah pengenalan anjing?
Nah, alih-alih mendefinisikan atribut seperti anjing secara manual, algoritma jaringan saraf dalam dapat mengidentifikasi atribut penting dan menangani semua kasus khusus tanpa pemrograman.
FAQ
1. Berapa lama waktu yang dibutuhkan untuk melatih jaringan saraf dalam?
Waktu yang dibutuhkan untuk melatih jaringan saraf dalam tergantung pada ukuran dataset dan kompleksitas model. Model sederhana bisa selesai dalam hitungan menit di laptop, sedangkan model besar seperti GPT atau ResNet bisa memakan waktu berhari-hari bahkan berminggu-minggu dengan GPU atau TPU berperforma tinggi.
2. Apakah saya bisa melatih DNN di komputer pribadi saya?
Ya, Anda bisa melatih jaringan saraf dalam di komputer pribadi jika dataset-nya kecil dan modelnya cukup sederhana. Namun, untuk melatih model besar atau menggunakan dataset besar, Anda memerlukan perangkat dengan GPU atau akses ke platform cloud seperti AWS atau Azure.
3. Apa perbedaan antara DNN untuk computer vision dan untuk pemrosesan bahasa alami?
Jaringan saraf dalam untuk computer vision menggunakan lapisan konvolusi (CNN) untuk memproses data piksel, sedangkan model NLP menggunakan arsitektur seperti transformer, LSTM, atau RNN untuk menangani struktur sekuensial dan semantik dalam bahasa. Keduanya menggunakan deep learning, namun dioptimalkan untuk jenis data yang berbeda.
4. Bagaimana cara menentukan jumlah hidden layer pada DNN?
Menentukan jumlah hidden layer pada DNN memerlukan eksperimen—terlalu sedikit bisa membuat model kurang belajar, terlalu banyak bisa menyebabkan overfitting dan memperlambat pelatihan. Mulailah dengan 1–3 lapisan untuk tugas sederhana dan tingkatkan secara bertahap, sambil memvalidasi performa dengan cross-validation atau data uji.
5. Terobosan besar apa yang diharapkan dalam riset jaringan saraf dalam?
Terobosan mendatang dalam riset jaringan saraf dalam meliputi jaringan saraf spars (yang mengurangi kebutuhan komputasi), neurosymbolic reasoning (menggabungkan logika dengan deep learning), teknik interpretabilitas yang lebih baik, serta arsitektur yang lebih hemat energi dan meniru efisiensi otak manusia (misalnya, spiking neural networks).


.webp)

